Crawlbase Review:
Is This Crawling API Worth Your Dev Time?
This Crawlbase review covers the web scraping API, Smart AI Proxy pricing, and free tier — so you know exactly what developers get for the money in 2026.
⚡ Quick Verdict
Crawlbase (formerly ProxyCrawl) is a developer-first web scraping API that charges only for successful requests — a rare approach in this space. With 1,000 free credits to start, complexity-tiered PAYG pricing that scales to $0.02 per 1,000 requests, automatic CAPTCHA bypass, JavaScript rendering, and a native MCP server for AI agents, it covers most scraping use cases under one account. The Smart AI Proxy adds rotating residential proxies for tougher targets. It’s not a point-and-click tool — you need to write code — but for developers scraping lightly to moderately protected sites, Crawlbase hits an unusually good price-to-capability ratio.
Developers and small businesses scraping at scale
You set up a scraper, run it overnight, and wake up to thousands of 403 errors, CAPTCHA walls, and IP bans. Now you’re debugging proxies, rotating user agents, and writing retry logic instead of actually using the data. Sound familiar?
This Crawlbase review cuts through the noise. Instead of maintaining your own proxy pool and anti-bot workarounds, Crawlbase lets you hand off a URL and get back clean HTML, JSON, or Markdown — and you only pay when the request actually succeeds.
The platform has been in this space since the ProxyCrawl days. The 2022 rebrand brought a broader product suite: a Crawling API, a Smart AI Proxy network, an async Enterprise Crawler, cloud storage for scraped results, and a Web MCP Server that plugs directly into AI tools like Claude and Cursor.
But is Crawlbase’s web scraping API good enough to replace your current setup? And how does Crawlbase pricing hold up against ScrapingBee and Bright Data? That’s what this review answers — with real numbers, not marketing copy.
What Is Crawlbase?
Crawlbase is a web data infrastructure platform that gives developers API access to a managed crawling and proxy network. You send it a URL, it handles the anti-bot bypassing, proxy rotation, and JavaScript rendering, and sends back the page content. No infrastructure to manage on your side. For teams that specifically need SERP API access, Crawlbase’s Crawling API supports Google result pages with geo-targeting built in.
The platform covers the full scraping stack:
- Crawling API — single endpoint for static and JS-rendered pages, with automatic CAPTCHA solving
- Smart AI Proxy — rotating proxy network with AI-powered IP management across 45+ countries
- Enterprise Crawler — async, large-scale crawling with webhook delivery and retry management
- Cloud Storage — serverless storage for crawled HTML, JSON, and screenshots
- Web MCP Server — live web access for Claude, Cursor, Windsurf, and other MCP-compatible AI clients
Company Background & Evolution
Crawlbase launched as ProxyCrawl, positioning itself as one of the original crawling-as-a-service providers. In 2022 it rebranded to Crawlbase to reflect the expanded product suite beyond just proxies. Today the platform claims 70,000+ companies as customers, including enterprises like Intel. The team is GDPR and CCPA compliant, and billing runs through Paddle.
The key differentiator that has stuck since the ProxyCrawl days: you only pay for successful requests. If Crawlbase fails to get you the page, the request doesn’t count. Most competitors charge regardless of whether the crawl worked.
Who Is Crawlbase For?

✓ Ideal Users
Crawlbase works best for people who write code and need managed crawling infrastructure:
- Backend developers — Building data pipelines, price monitors, or SERP trackers in Python, Node.js, Go, Ruby, PHP, Java, or C#. Crawlbase has official SDKs for all of them.
- Small SaaS teams — Need reliable scraping without hiring a proxy engineer. The PAYG model keeps costs predictable and tied to actual results.
- eCommerce intelligence teams — Monitoring Amazon, Walmart, eBay, and competitor pricing at scale. Crawlbase handles the blocks these sites throw at scrapers. If you also run eBay proxies in a separate setup, Crawlbase’s Smart AI Proxy can replace that layer.
- AI/LLM developers — Building RAG pipelines or AI agents that need live web data. The MCP Server plugs directly into Claude Desktop, Cursor, and Windsurf in under a minute.
- Data agencies — Running multi-client scraping operations who want a single account covering crawling, proxy rotation, storage, and async jobs. If you need a dedicated private proxy layer for specific clients, Crawlbase’s proxy network supports that too.
✗ Not Ideal For
Skip Crawlbase if you:
- Need a no-code scraper with a point-and-click UI (use Apify or Octoparse instead)
- Are targeting heavily fortified sites like LinkedIn at scale (the $15/1,000 LinkedIn rate adds up fast)
- Need a high-volume residential proxy on a pure bandwidth model (Bright Data or Oxylabs offer that)
- Want phone support — Crawlbase is ticket and chat only
Crawlbase Features & What You Get
Crawlbase isn’t one product — it’s a suite of five tools sharing one account and one token system. Here’s what each piece does:
Crawling API — Core Product
- Single GET/POST endpoint at
https://api.crawlbase.com/— one URL handles static HTML, JavaScript-rendered SPAs, and everything in between - Two token types: Normal Token for static/HTML pages, JavaScript Token for headless browser rendering (React, Angular, Vue)
- Automatic CAPTCHA solving — Cloudflare, PerimeterX, DataDome, hCaptcha handled without any extra configuration
- Geo-targeting in 30+ countries — pass
country=US(or DE, JP, BR, etc.) to exit from a specific location - Device emulation — desktop, tablet, or mobile user-agent profiles
- Custom headers and cookies — forward your own request headers and session cookies
- Screenshot capture — returns JPEG screenshots, stored for up to 1 hour
- Markdown output — pass
format=mdto get clean Markdown instead of raw HTML (useful for LLM pipelines) - Async mode — queue long-running crawls and retrieve results via webhook or Cloud Storage
- Sticky sessions —
cookies_sessionkeeps the same proxy for up to 300 seconds - No bandwidth limits — pull as much data as you need per request
What “pay for success only” means in practice: Crawlbase only counts a request toward your bill when it returns a pc_status: 200. If Cloudflare blocks the crawl, if the site is down, or if the request times out, you pay nothing. ScraperAPI and most alternatives charge for every attempt — blocked or not.
Smart AI Proxy
- Standard HTTP/HTTPS rotating proxy on host
proxy.crawlbase.com:8012 - AI-powered IP rotation — machine learning selects and rotates IPs to minimize blocks, not just random round-robin
- Datacenter + residential proxies (residential included in Advanced and Premium plans)
- 100,000 unique proxies on Starter/Advanced; 1,000,000+ on Premium
- 45+ country geolocation support
- JavaScript rendering available (counts as 2 credits per request)
- 30-day free trial — 5,000 credits, no credit card required
Enterprise Crawler (Async)
- Asynchronous PUSH/PULL system for large-scale jobs
- Crawlbase manages the queue, retries (up to 110 over 48 hours), and delivery
- Webhook-based data delivery or direct push to Cloud Storage
- Real-time monitoring dashboard showing queued, active, and retrying requests
- Custom pricing — contact Crawlbase sales
Cloud Storage
- Add
&store=trueto any Crawling API call to auto-save the result - Stores HTML, JSON, screenshots, and extracted data
- Retrieve by RID (request ID) via
GET https://api.crawlbase.com/storage?token=TOKEN&rid=RID - Free tier: 10,000 documents, 14-day retention
- Paid tiers up to 1M+ documents with 30-day retention
Web MCP Server (Free)
- Connects Claude Desktop, Cursor, Windsurf, VS Code, ChatGPT, and any MCP-compatible client to live web data
- Setup in under a minute via
npx @crawlbase/mcp@latest— no separate server needed - Three tools:
crawl(live HTML),crawl_markdown(clean Markdown),crawl_screenshot(page screenshot) - Free to use — only underlying Crawling API credits are consumed
- Open source at github.com/crawlbase/crawlbase-mcp
How Crawlbase Works (Step-by-Step)
Getting your first successful crawl takes about five minutes. Here’s the flow from signup to live data:
Step 1: Create a Free Account
Go to crawlbase.com and click “Try It Free.” You can sign up with Google, GitHub, or email — no credit card required. Your account is created with 1,000 free Crawling API credits already loaded. You also get access to the 30-day Smart AI Proxy free trial (5,000 credits, datacenter proxies).
Step 2: Grab Your API Token
Inside the dashboard you’ll see two tokens: a Normal Token for static pages and a JavaScript Token for JS-rendered sites. Copy the one you need. The difference matters — using the JS Token on a plain HTML site is slower and costs more credits unnecessarily.
Step 3: Make Your First API Call
Send a GET request to https://api.crawlbase.com/?token=YOUR_TOKEN&url=https://example.com. That’s the whole call. No SDK required, though Crawlbase provides official libraries for Python, Node.js, Ruby, PHP, Go, Java, and C#. Add optional parameters as you go: country=US for geo-targeting, format=md for Markdown output, store=true to save to Cloud Storage.
Step 4: Handle the Response
The API returns the page content plus metadata headers: pc_status (Crawlbase’s success code), original_status (the site’s HTTP status), url, and rid (the request ID for storage retrieval). A pc_status: 200 means success and counts against your credits. Any other value is free.
Step 5: Scale with Async or Proxy Mode
For bulk jobs, switch to async mode by adding &callback=true&crawler=YourCrawlerName — Crawlbase queues requests and pushes results to your webhook. For browser automation or tools that expect a standard proxy, switch to the Smart AI Proxy and point your HTTP client to proxy.crawlbase.com:8012.
Bottom line: If you can write a single GET request in any language, you can be pulling clean page data within minutes. The API is genuinely simple — the complexity is in Crawlbase’s infrastructure, not in your code.
Crawlbase Pricing & Plans
Crawlbase splits pricing across its two main products. The Crawling API is pure PAYG — you pay per successful request with volume discounts. The Smart AI Proxy is subscription-based. Cloud Storage has its own monthly tiers. Here’s what you actually need to know:
Crawling API — Pay-As-You-Go (per 1,000 requests)
| Volume Tier | Standard | Moderate | Complex |
|---|---|---|---|
| 0 – 1,000 requests | $3.00 | $4.50 | $6.00 |
| Next 10,000 requests | $2.00 | $3.00 | $4.00 |
| Next 100,000 requests | $0.60 | $0.90 | $1.20 |
| Next 1,000,000 requests | $0.50 | $0.75 | $1.00 |
| Next 10,000,000 requests | $0.10 | $0.15 | $0.20 |
| Next 100,000,000 requests | $0.05 | $0.07 | $0.10 |
| Next 1,000,000,000 requests | $0.04 | $0.06 | $0.08 |
| After 1 billion requests | $0.02 | $0.03 | $0.04 |
Important: Crawlbase assigns the complexity tier (Standard, Moderate, or Complex) based on the target site’s anti-bot difficulty — not your choice. Sites like Amazon or LinkedIn fall into higher tiers. LinkedIn has separate fixed pricing at $15.00 per 1,000 successful crawls, and free credits do not apply to LinkedIn requests.
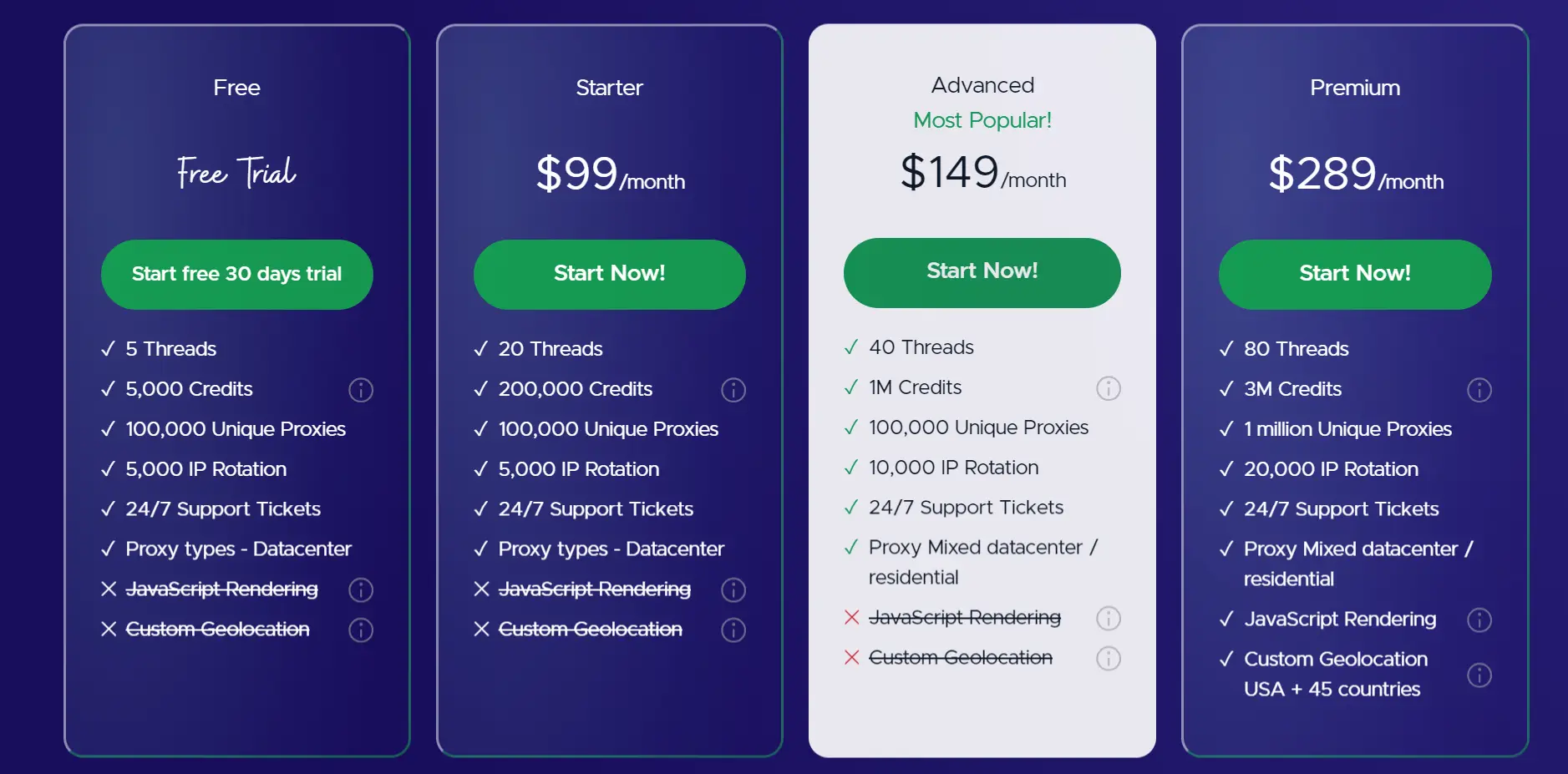
Smart AI Proxy — Monthly Subscription
| Plan | Monthly Price | Annual Price | Threads | Credits/Month | Proxy Types |
|---|---|---|---|---|---|
| Free Trial | $0 (30 days) | — | 5 | 5,000 | Datacenter only |
| Starter | $149/mo | $1,599/yr | 20 | 200,000 | Datacenter |
| Advanced | $229/mo | $2,249/yr | 40 | 1,000,000 | DC + Residential |
| Premium | $449/mo | $4,140/yr | 80 | 3,000,000 | DC + Residential |
Cloud Storage pricing: Free (10,000 docs, 14-day retention) | Developer $29/mo (100,000 docs) | Business $249/mo (1,000,000 docs).
Free trial: Crawling API gives you 1,000 requests on signup — no credit card. Smart AI Proxy offers 30 days free with 5,000 credits. Cloud Storage has a permanent free tier.
Refund policy: Smart AI Proxy plans include a 24-hour satisfaction guarantee — if you’re not happy within 24 hours of payment, you get a full refund, no questions asked. No long-term contracts — cancel anytime.
Pros & Cons
Pros ✓
- Pay for success only: Failed and blocked requests cost you nothing — genuinely rare in this market
- Aggressive volume discounts: Standard tier drops from $3.00/1k to $0.02/1k at massive scale
- Free tier to start: 1,000 Crawling API credits with no credit card, plus a 30-day proxy trial
- Native MCP server: Live web data inside Claude, Cursor, Windsurf in about a minute — and it’s free to set up
- Single API handles JS and static: Switch token types rather than managing two separate services
- No bandwidth limits: No GB caps on any product
- All-in-one account: Crawling API, proxy, storage, crawler, and MCP under one dashboard and token
- GDPR & CCPA compliant: Matters for regulated industries and EU users
- SDKs in 7 languages: Python, Node.js, Ruby, PHP, Go, Java, C#
- Tor network support: Can crawl .onion sites via
tor_network=true
Cons ✗
- Developer-only product: No visual scraper or no-code workflow builder
- Smart AI Proxy is subscription, not PAYG: If you need proxy access only occasionally, $149/mo is steep
- Trustpilot score is 3.7/5: Low review count makes this hard to interpret, but it’s a yellow flag
- LinkedIn costs $15/1,000: Premium price, free credits excluded, public pages only
- Tier assignment is opaque: Crawlbase decides whether your target is Standard, Moderate, or Complex — you can’t override it
- ~22 explicit geo-targets: The Crawling API country list is smaller than some competitors’ residential networks
- Response latency: 4–10 seconds per request is fine for batch jobs, not for real-time user-facing features
Bottom Line: Crawlbase is a strong value play if you write code and need scraping to just work without managing proxies yourself. The success-based billing is the biggest differentiator. The main friction is the subscription-only Smart AI Proxy and the opaque tier assignment for the Crawling API.
Crawlbase vs ScrapingBee, Bright Data: Full Comparison
Crawlbase operates in a crowded space. Here’s how it stacks up against two key competitors developers frequently evaluate alongside it:
Crawlbase vs ScrapingBee
| Feature | Crawlbase | ScrapingBee |
|---|---|---|
| Pricing model | PAYG (success-only) | Monthly subscription (credits) |
| Entry-level price | $3.00 / 1,000 requests (PAYG) | ~$49/mo (150,000 API credits — per ScrapingBee pricing page) |
| Free tier | 1,000 requests, no card | 1,000 credits trial |
| JS rendering | Yes (JS Token, headless browser) | Yes (included) |
| CAPTCHA bypass | Automatic (Cloudflare, DataDome, etc.) | Automatic (Cloudflare, reCAPTCHA) |
| Pay for failures? | No — failed requests are free | Yes — credits consumed regardless |
| Geo-targeting | 30+ countries | Premium proxies only (limited geo) |
| Cloud storage | Yes (built-in, free tier) | No |
| MCP / AI integration | Yes (native MCP Server, free) | No |
| Async crawler | Yes (Enterprise Crawler) | No (sync only) |
| Success rate (stated) | 99% | ~97–98% (general claim) |
| Best for | PAYG scraping at scale, AI pipelines | Simple scraping with a clean API |
Winner for Value: Crawlbase (PAYG + no charge on failure) | Winner for Simplicity: ScrapingBee (slightly simpler setup) | Winner for AI/Async: Crawlbase (MCP server + Enterprise Crawler)
Crawlbase vs Bright Data (Web Scraper API)
| Feature | Crawlbase | Bright Data |
|---|---|---|
| Pricing model | PAYG per 1,000 requests | Per 1,000 requests (PAYG or plans) |
| Entry price (scraping API) | $3.00 / 1,000 (Standard) | ~$1.50–$3.00 / 1,000 (varies by product) |
| Proxy pool (residential) | 140M IPs (Crawlbase residential network total) | 150M+ IPs |
| Geo coverage | 30+ countries (Crawling API) | 195+ countries |
| CAPTCHA bypass | Automatic, included | Automatic, included |
| JS rendering | Yes (headless browser) | Yes (Scraping Browser) |
| Free tier | 1,000 credits, no card | Trial credit available |
| No-code tools | No | Yes (IDE, no-code scrapers) |
| MCP server | Yes (free) | No |
| Minimum spend | None (pure PAYG) | $500/month minimum (some products) |
| Overall cost at scale | Crawlbase claims 2.6× cheaper (per Crawlbase pricing page) | Higher, especially for residential |
| Best for | Developers on tight budgets, AI pipelines | Enterprise teams needing global geo + compliance |
Winner for Budget: Crawlbase (PAYG, no minimums, success-only billing) | Winner for Enterprise Scale: Bright Data (larger geo coverage, no-code tools, compliance certifications) | Winner for AI Integration: Crawlbase (MCP server)
🏆 Choose Crawlbase When:
- You want PAYG pricing with zero charge for failed requests
- You’re building AI pipelines and need an MCP-native web data source
- You want a single platform for crawling, proxies, storage, and async jobs
- Your budget is tight and you can’t afford Bright Data’s minimums
- You’re scraping lightly to moderately protected sites
🔍 Choose Competitors When:
- You need 195-country geo coverage (Bright Data wins here)
- You want a no-code scraper interface (Apify, Octoparse)
- You need a simpler credit-based API without complexity tiers (ScrapingBee)
- You’re targeting extremely well-defended sites at massive scale (Bright Data, Oxylabs)
- You need dedicated account management and SLA guarantees
Ratings Breakdown
Here’s our category-by-category score based on product testing, documented performance claims, and user feedback across platforms:
| Category | Score | Notes |
|---|---|---|
| Pricing & Value | 4.5 / 5 | Success-only PAYG billing and volume discounts are genuinely competitive. Smart AI Proxy subscription adds cost for proxy users. |
| Ease of Integration | 4.2 / 5 | Single endpoint, clear docs, SDKs in 7 languages. Two-minute integration for experienced devs. Not beginner-friendly for non-coders. |
| Anti-Bot Capabilities | 4.0 / 5 | Handles Cloudflare, DataDome, PerimeterX, hCaptcha automatically. Very challenging targets (LinkedIn, major retailers) hit premium tiers or limits. |
| Reliability & Uptime | 4.0 / 5 | 99% stated success rate, 99.9% network uptime. Trustpilot score (3.7/5) pulls this down — though Capterra rates 4.8/5. |
| Features & Product Breadth | 4.3 / 5 | Crawling API + Smart Proxy + Cloud Storage + MCP Server under one account is genuinely comprehensive. Tor support and Markdown output are niche but useful. |
| Support & Documentation | 3.8 / 5 | Good docs with parameter references and SDK guides. 24/7 ticket support. No phone support. Response quality varies by plan tier. |
| Overall Rating | 4.1 / 5 | Solid developer tool with standout pricing model. Best for code-first teams scraping at scale. |
Rating Summary: Crawlbase earns its highest marks on value — the success-only billing and volume discounts are hard to match at lower request volumes. Integration is smooth for any developer familiar with REST APIs. The main drag on the overall score is the split Trustpilot signal and the subscription-only proxy pricing, which doesn’t fit every use case.
Is Crawlbase Worth It? Legit & Safe Review
Legitimacy & Safety
- ✓ Established platform — Operating since the ProxyCrawl era, with 70,000+ customers including Fortune 500 names like Intel. Not a new or fly-by-night service.
- ✓ GDPR & CCPA compliant — Stated compliance with both frameworks. Relevant if you’re scraping for regulated industries or storing EU user data.
- ✓ Secure payment processing — Billing handled by Paddle, a well-established merchant of record. Your card details never touch Crawlbase directly.
- ✓ No credit card for free tier — You can test the Crawling API with 1,000 real requests before entering any payment information.
- ✓ Third-party review scores — Capterra: 4.8/5, Software Advice: 4.8/5. Trustpilot is lower at 3.7/5, but the review count there is much smaller.
Long-Term Reliability
The platform has been stable through the ProxyCrawl-to-Crawlbase rebrand and product expansion. Key reliability indicators:
- API versioning and docs — Parameters are well-documented and have been consistent. No reports of sudden breaking changes.
- 99.9% uptime SLA — Standard for API infrastructure; backed by a status page at crawlbase.com/status.
- Active GitHub — SDKs and MCP Server are open source and actively maintained.
- No-lock-in billing — PAYG for the Crawling API means you can stop or scale any time. Subscriptions can be cancelled monthly.
Keep this in mind: Crawlbase is a scraping infrastructure tool, not a legal clearance service. It’s your responsibility to ensure that the data you collect complies with the target website’s terms of service and applicable laws. Crawlbase’s GDPR compliance covers their data handling — not what you do with scraped data afterward.
Worth It? Final Verdict
✓ YES, Crawlbase Is Worth It If:
- You write code and need managed anti-bot scraping without proxy headaches
- You’re on a variable budget and want to pay only for successful results
- You’re building AI pipelines or LLM tools that need live web data
- You want one account covering crawling, proxies, storage, and async jobs
- You’re scraping e-commerce, SERP, travel, or real estate data at moderate scale
✗ NO, Look Elsewhere If:
- You need a no-code scraper with a point-and-click interface
- You only need proxies occasionally — $149/mo Smart AI Proxy won’t make sense
- You need global residential proxy coverage across 195+ countries
- Your primary target is LinkedIn at high volume ($15/1,000 is expensive)
- You need dedicated support, SLA contracts, or account management
Our Recommendation: Crawlbase is a legitimate, well-built platform for developer-driven scraping. The success-only PAYG pricing model is the clearest reason to choose it over subscription-based alternatives — you’re not paying for failures. Start with the 1,000 free credits, test it against your actual target sites, and use the 30-day Smart AI Proxy trial if you need rotating residential IPs. The free tier is generous enough to know within an hour whether it works for your specific use case.
Crawlbase Review: Frequently Asked Questions
What is Crawlbase and what is it used for?
Crawlbase is a web scraping API and proxy infrastructure platform. You send it a URL, it returns the page content — bypassing CAPTCHAs, JavaScript rendering, and anti-bot systems automatically. It’s used for price monitoring, SERP scraping, lead generation, competitive research, AI data pipelines, and any other task requiring large-scale web data collection. Formerly called ProxyCrawl, it rebranded to Crawlbase in 2022.
Is Crawlbase free to try?
Yes. You get 1,000 free Crawling API requests on signup with no credit card required. The Smart AI Proxy also offers a 30-day free trial with 5,000 credits and datacenter proxies. Cloud Storage has a permanent free tier with 10,000 document slots and 14-day retention. The Web MCP Server is free to use — you only consume your existing Crawling API credits when it makes requests.
Does Crawlbase bypass Cloudflare?
Yes, for most Cloudflare-protected pages. The Crawling API includes automatic CAPTCHA solving and anti-bot bypass for Cloudflare, PerimeterX, DataDome, and hCaptcha. Sites using Cloudflare’s most aggressive bot management may be assigned to the Complex pricing tier, which costs more per request. If Crawlbase fails to get through, you aren’t charged — failed requests are free.
How does Crawlbase pricing work?
The Crawling API uses pay-as-you-go pricing based on two factors: the complexity tier of your target site (Standard at $3.00/1k, Moderate at $4.50/1k, or Complex at $6.00/1k to start) and volume (prices drop steeply with scale). You only pay for successful requests. The Smart AI Proxy is a monthly subscription starting at $149/month. Cloud Storage starts free. There are no monthly minimums on the Crawling API.
What is the difference between Crawlbase’s Normal Token and JavaScript Token?
Both tokens use the same API endpoint. The Normal Token fetches static HTML using a standard HTTP connection — fast and cheap, suited for any site that doesn’t require JavaScript to render content. The JavaScript Token spins up a headless browser to fully render the page — necessary for single-page applications built in React, Angular, or Vue. JS Token requests are slower (4–10+ seconds) and cost more credits, so only use them when you actually need JavaScript execution.
What was ProxyCrawl — is it the same as Crawlbase?
Yes. If you’re reading a ProxyCrawl review from before 2022, it describes the same platform now called Crawlbase. ProxyCrawl was the original brand name when the platform launched as one of the first crawling-as-a-service APIs. In 2022, the company rebranded to Crawlbase to reflect its expanded suite beyond just proxy crawling — adding Cloud Storage, the Enterprise Crawler, and the Web MCP Server. Existing ProxyCrawl accounts, tokens, and integrations continued working through the rebrand without interruption.
What is the Crawlbase MCP Server and how does it work?
The Web MCP Server is a free tool that connects Crawlbase’s Crawling API to any Model Context Protocol (MCP) compatible AI client — Claude Desktop, Cursor, Windsurf, VS Code, ChatGPT, and others. Once configured (one config file edit, runs via npx @crawlbase/mcp@latest), your AI assistant can fetch live web pages, get clean Markdown from any URL, or capture screenshots during conversations. The MCP server itself is free and open source; it consumes your regular Crawling API credits per request.
Can Crawlbase scrape Amazon, LinkedIn, or Google?
Yes, but with important caveats:
- Amazon and Google: Supported, but these sites fall into higher complexity tiers (Moderate or Complex), so costs per request are higher than for simpler sites.
- LinkedIn: Public LinkedIn pages are supported at a fixed rate of $15.00 per 1,000 successful crawls. Free credits do not apply, and only publicly visible pages (not logged-in content) can be crawled.
- Always verify that your scraping complies with each platform’s terms of service.
Is Crawlbase better than ScraperAPI for web scraping?
For most developers, Crawlbase’s billing model is the deciding factor. Crawlbase charges only for successful requests — if it can’t get past the anti-bot system, the request is free. ScraperAPI charges credits regardless of whether the request succeeded. Crawlbase also includes cloud storage and an async crawler in the same account, which ScraperAPI lacks. ScraperAPI’s subscription model can be cheaper for consistent medium-volume usage, while Crawlbase’s web scraping API pricing is better when success rates vary or volume is unpredictable.
Does Crawlbase have a refund policy?
For Smart AI Proxy plans, Crawlbase offers a 24-hour satisfaction guarantee — if you’re not satisfied within 24 hours of payment, you get a full refund with no questions asked. The Crawling API is PAYG with no monthly commitment, so there’s no subscription to cancel. Annual Smart AI Proxy plans are discounted (11–19% savings) but are treated as single payments, so review the terms before committing to annual billing.
What programming languages does Crawlbase support?
Crawlbase provides official SDKs for Python, Node.js, Ruby, PHP, Go, Java, and C#/.NET. The underlying API is a standard REST endpoint (GET/POST), so any language capable of making HTTP requests works without an SDK. The MCP Server is distributed as an npm package and works via command line on any system with Node.js installed.
How is the Crawlbase Smart AI Proxy different from the Crawling API?
Yes — they’re complementary products built for different integration patterns. The Crawling API is a managed service: you send a URL, Crawlbase handles everything, and you receive the content back. It’s the simpler approach for most scraping tasks. The Smart AI Proxy behaves like a standard rotating proxy — you point your HTTP client, browser, or scraping framework at proxy.crawlbase.com:8012 and traffic routes through Crawlbase’s IP network. Use the proxy when you need full control over your requests and session handling, or when you’re integrating with tools that expect a proxy configuration rather than an API call.
Crawlbase Review: Final Verdict
Crawlbase is a well-built, developer-focused web scraping API that earns its spot on any developer’s shortlist in 2026 — not because it’s flashy, but because the billing model is honest. You pay for results, not attempts. That single design decision separates it from most competitors. Add the free tier, the all-in-one product suite, and first-class MCP support for AI tooling, and Crawlbase makes a strong case for any team that writes code and needs scraping to work reliably without managing proxies in-house.
It isn’t for everyone. If you need a no-code scraper, global residential coverage across 195 countries, or dedicated enterprise support, Bright Data or Apify will serve you better. But for developers who want a clean API, honest pricing, and the infrastructure burden off their plate, Crawlbase is worth a serious look.
✓ What We Love
- Success-only billing — no charge on failed crawls
- 1,000 free credits, no card required
- Volume discounts down to $0.02 per 1,000 requests
- Native MCP server for Claude, Cursor, Windsurf
- All five products under one account and token
- Markdown output for LLM-ready data pipelines
- No bandwidth limits on any product
✗ What Could Be Better
- Smart AI Proxy is subscription-only (not PAYG)
- No no-code or visual scraper interface
- Trustpilot score of 3.7/5 (low review count)
- LinkedIn crawling costs $15/1,000 — pricey
- Complexity tier assignment is opaque
Ready to Start Scraping Without the Proxy Headaches?
Crawlbase gives you 1,000 free API credits and a 30-day proxy trial — no credit card, no commitment.
Try Crawlbase Free Now →